当社は、静岡県立中央図書館と共同で、地域資料収集の一環として静岡県内の自治体Webサイトにアップロードされた要項・要領、広報誌、行政資料等の自治体資料のPDFを自動収集するシステムを開発いたしましたので、お知らせいたします。
■開発の背景
従来、自治体資料は紙媒体で発行されており、図書館はこれらを地域資料として収集、整理、保存、提供してきました。静岡県立中央図書館における自治体資料の納本は、県の他部署向けには要綱を定め、市町向けには文書を通じて依頼をしておりました。一方、昨今では、自治体が自らのWebサイトを持つことが珍しくなくなり、Webサイトに自治体資料をアップロードするのみで、紙媒体の発行は行わない例も多くなり、紙媒体として発行された自治体資料を対象とした従来の要綱及び文書において、Webサイトにしかない自治体資料は納本の対象外となっていました。
このことについて、静岡県立中央図書館では人手による収集を行っておりましたが、収集漏れや職員の負担の削減と効率化を図り図書館のDX化を推進するため、静岡県立中央図書館と当社は共同でWebサイトクローリングシステムを開発いたしました。
■システム概要
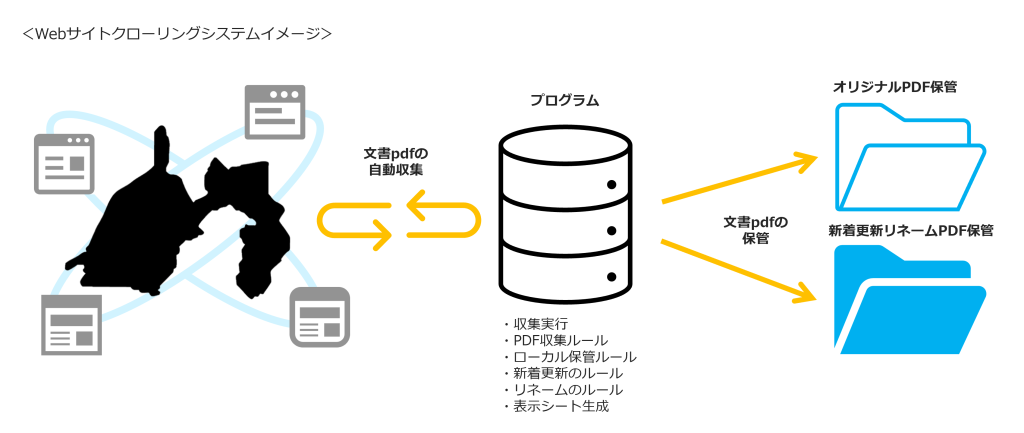
この度開発したWebサイトクローリングシステムでは、静岡県内の自治体Webサイトを対象とし、ドメイン内に格納されているPDFを自動かつ定期的に巡回し、情報を取得・保存(以下、クローリング)します。収集したPDFはGoogle Driveで収集した日付毎に、収集元のドメインと同じディレクトリ構造で保存・管理されます。
初回のクローリングでは、その時点におけるクローリング範囲内にあるPDFを全て収集し、2回目以降は前回との差分ファイル(含む更新)を収集します。さらに収集したPDFの保管名称を一定の規則に沿って自動で変換するリネーム機能を実装し、人手による作業を極力減らし、膨大なデジタル文書の収集を効率的に行うことが可能になります。
当社は今後も静岡県立中央図書館と協力し、システム精度の向上及び機能拡充を行うとともに、公共図書館が活用できるサービスの開発に向けた取り組みを検討してまいります。